前陣子在研究 llama.cpp 框架支援的 KV Cache 操作,順手將一些常用或者有關 KV Cache 的參數記錄一下。預設值用粗體表示,隨時可能會變所以僅供參考。
llama-server 參數
https://github.com/ggml-org/llama.cpp/tree/master/tools/server
| |
- -m [gguf模型]
- -np [N]:Slots 數量(可同時處理的 requests)
- -c [N]:Context window size。預設 0 表示從模型 metadata 讀取
KV 量化
- -ctk [f32, f16, bf16, q8_0, q4_0, q4_1, iq4_nl, q5_0, q5_1]:Key cache 量化格式
- -ctv [f32, f16, bf16, q8_0, q4_0, q4_1, iq4_nl, q5_0, q5_1]:Value cache 量化格式
Offloading
- -ngl [N|auto|all]:放在 GPU 的模型層數。CPU + GPU 混合推論是 llama.cpp 的特色。auto是2025年底這個 PR 新加的…
- -kvo/-nkvo:KV Cache 是否要 offload 到 GPU
- –mlock:把模型檔案 lock 在 RAM,避免被 OS swapping 到 disk
- –mmap/–no-mmap:是否 mmap 模型,預設開啟(甚麼時候會想關掉?例如特定情況想減少 pageout 時)
- -ts [N0,N1,N2]:模型 offload 到 GPU 的比例,例如雙 GPU 給 [3,1]
Context Shift
Prompt + generated tokens 超過 context window size 就不會報 error 了;反之會自動丟棄最前面的訊息
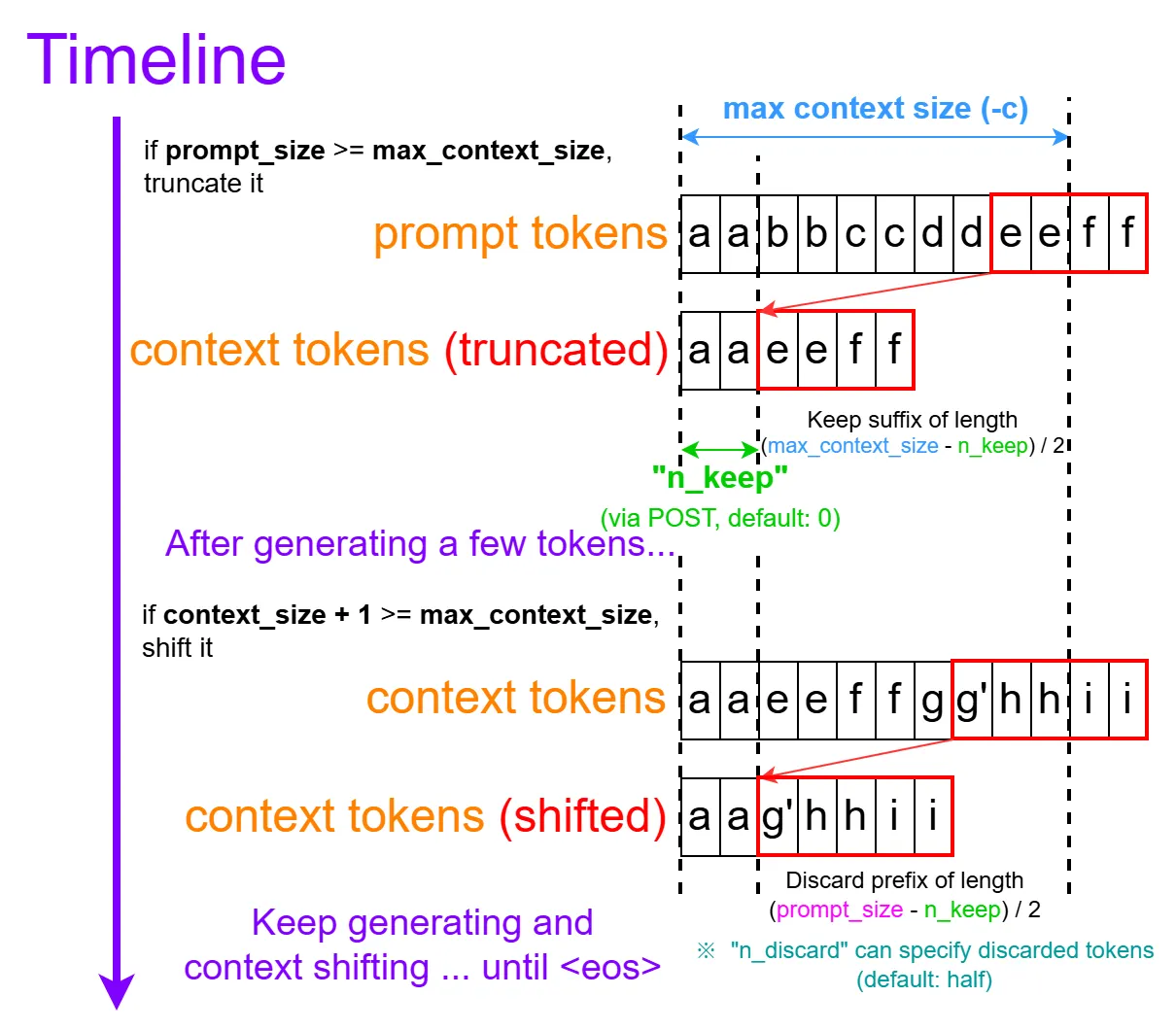
- –context-shift/–no-context-shift (2025/08 預設變 disabled):解決長文問題;context 超過 window size 時會 truncate
- -keep [N]:位移時想保留的 initial prompt tokens 數量。預設 0。
system prompt 通常不想被丟棄,這時就會用到 keep
KV Shifting
讓 prompt 前綴不用完全一樣也可以複用 KV Cache(模型需要是 RoPE)
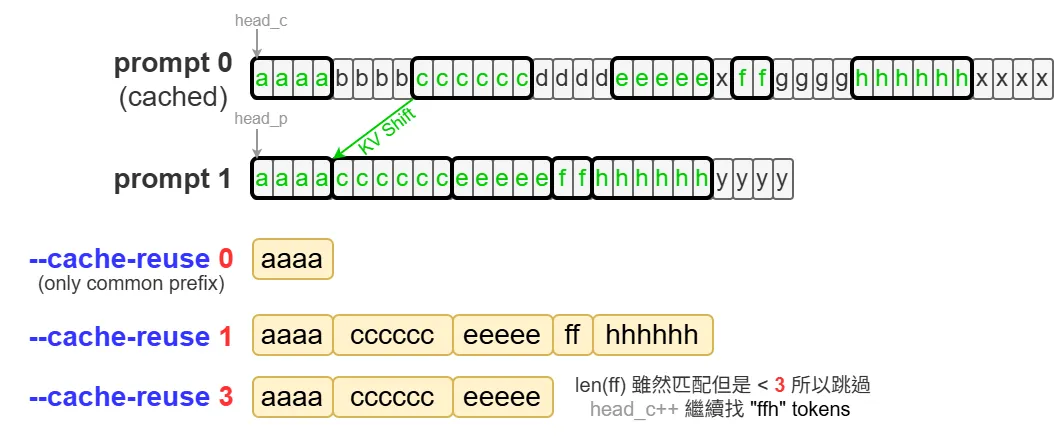
- –cache-reuse [N]:透過 KV Shifting 複用 KV 時的最小 chunk size。預設 0 表示不啟用
Chunk size 太小有個缺點:復用的 KV Cache 意義上可能會不一樣
Slots 相關
- –slot-save-path [路徑]:存放 KV Cache of slots 的位置
常見 KV Cache 優化 (預設都開啟)
- -fa [on|off|auto]:FlashAttention
- -cb/-nocb:Continous Batching
- –cache-prompt/–no-cache-prompt:啟用 Prompt caching(複用同 slot 上一筆 prompt 的 KV Cache)
Server API Endpoints
POST /completion (not OAI-compatible)
| |
| |
- “cache_prompt”:啟用 Prompt caching(複用同 slot 上一筆 prompt 的 KV Cache)。預設打開
- “id_slot”:指定的 slot。預設 -1,Server 會選擇 idle slot 中相似度最高的 (common prefix/input tokens)
KV slots 操作
- POST /slots/{id_slot}?action=save (將 slot N 的 KV cache 寫到指定 filename)
- POST /slots/{id_slot}?action=restore (將 filename 內的 KV cache 讀到 slot N)
- POST /slots/{id_slot}?action=erase (刪掉 slot N 的 KV Cache)
GET /slots
- 查看所有 slots 狀態